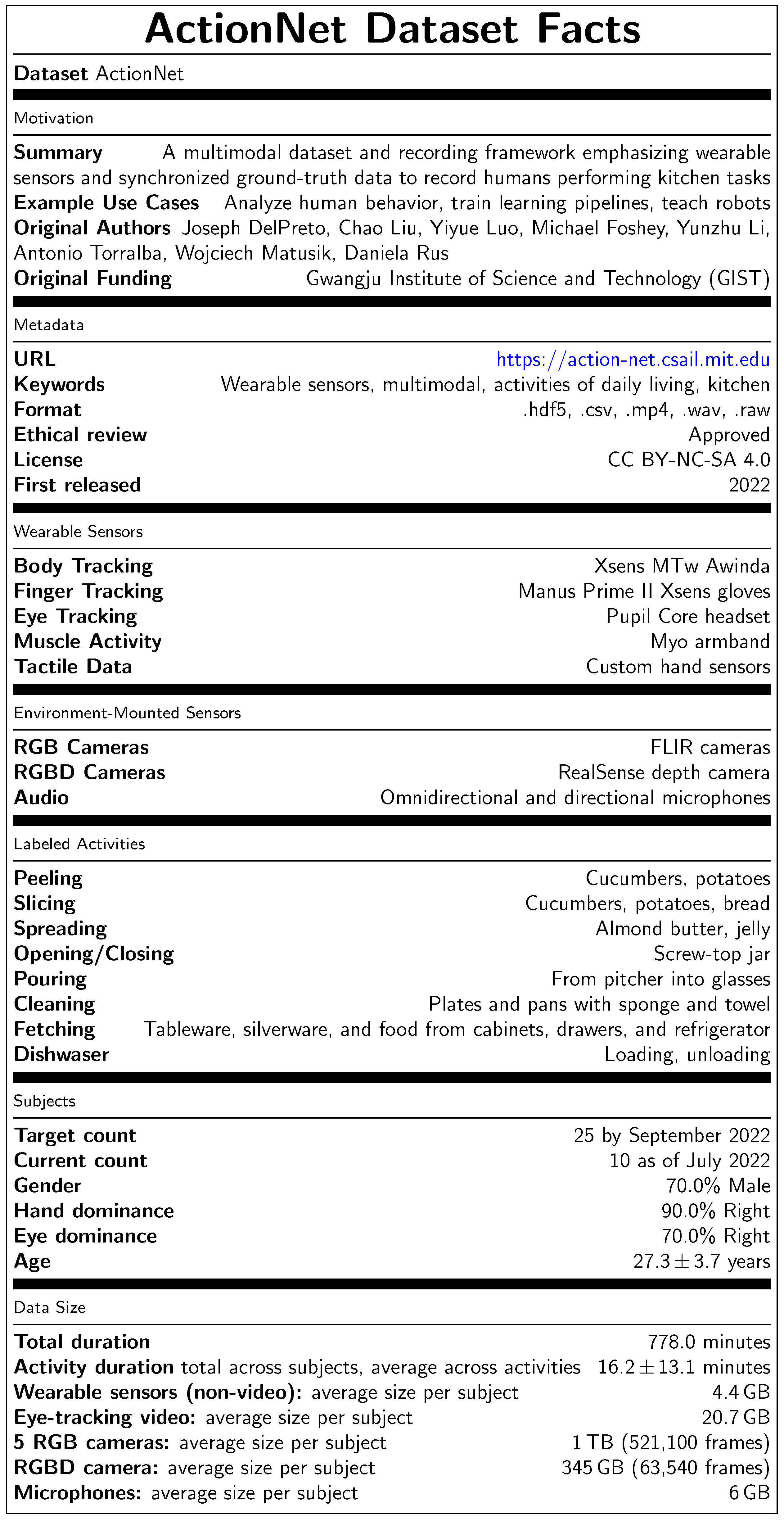
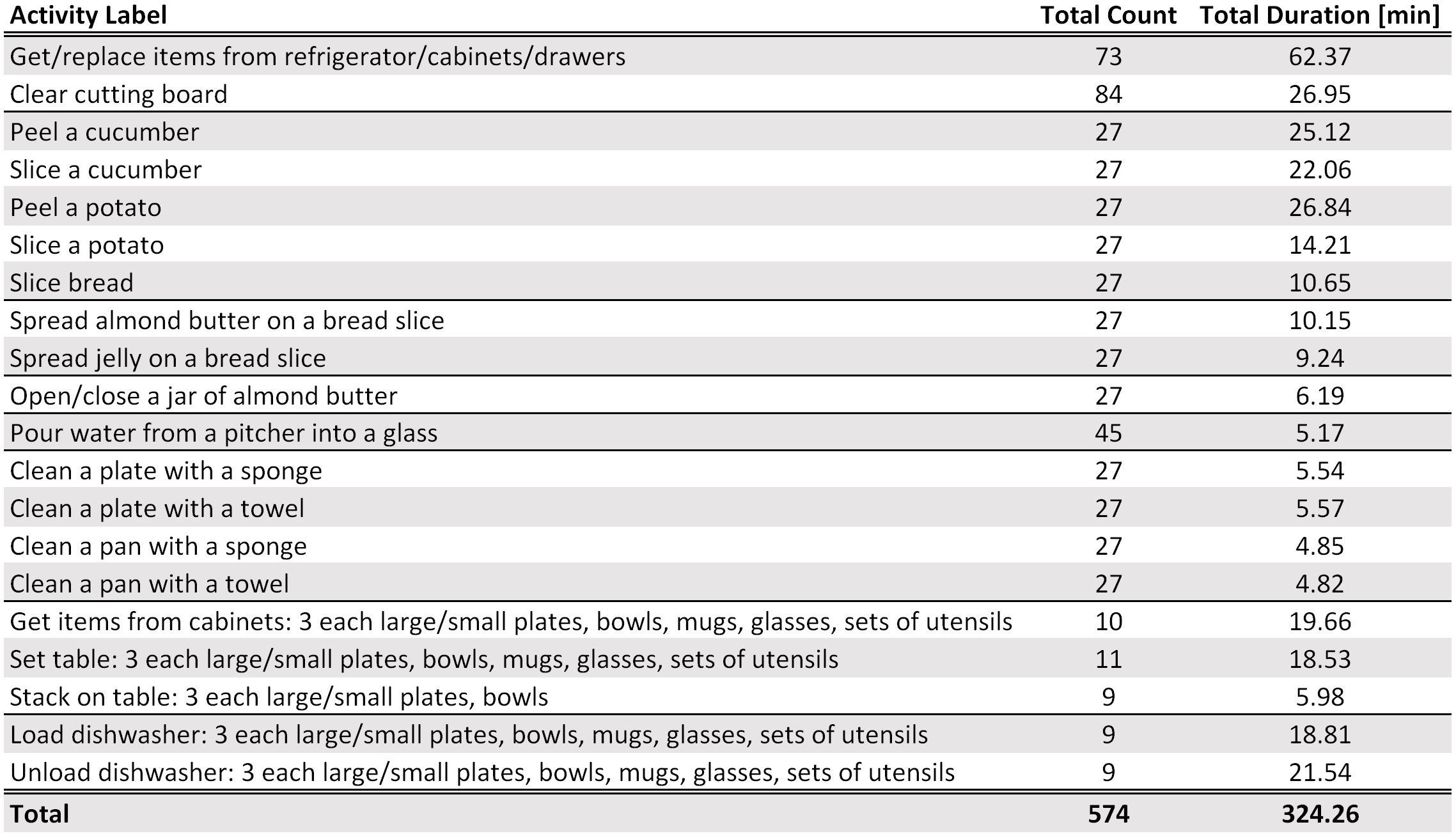
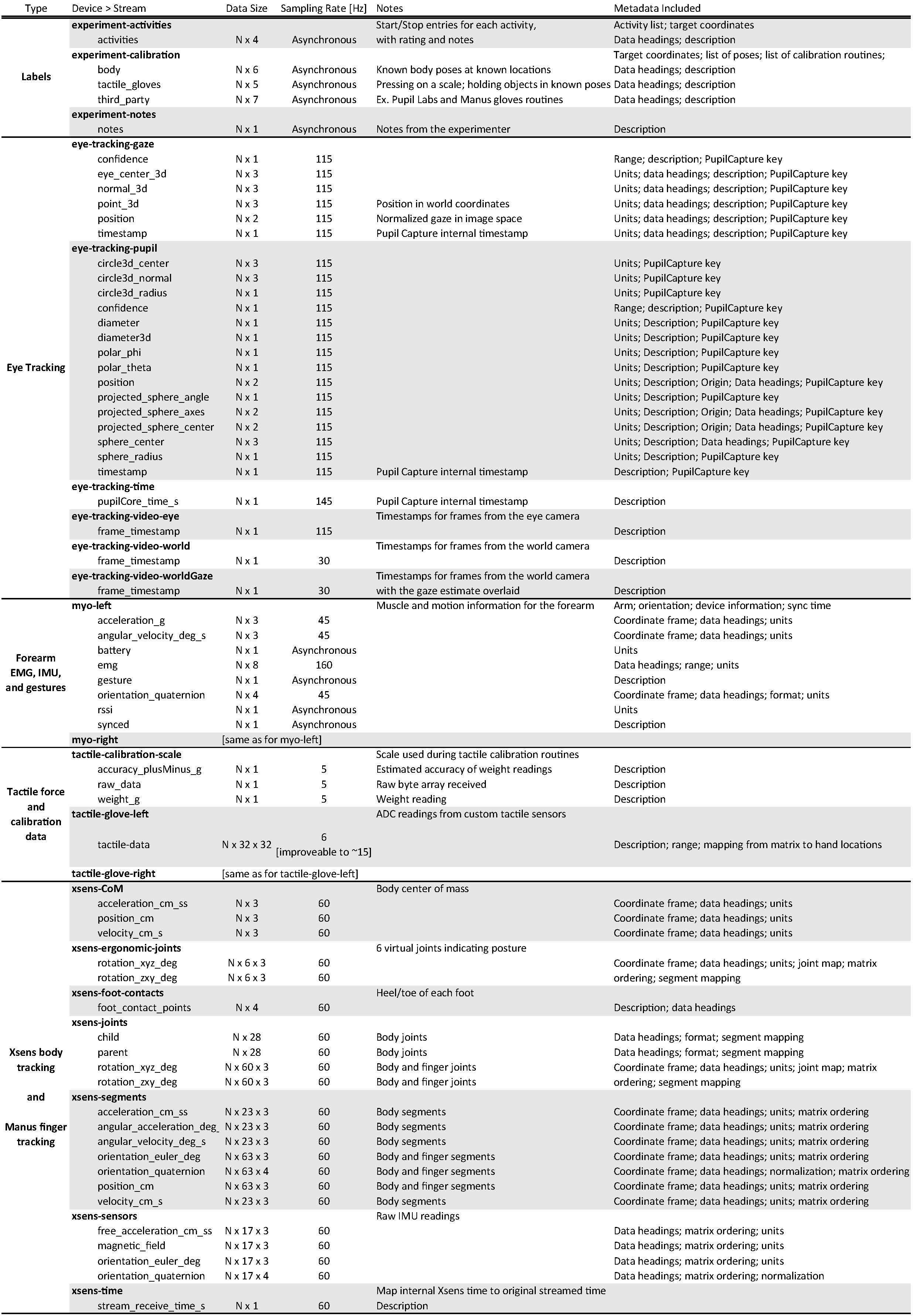
Wearable Sensors
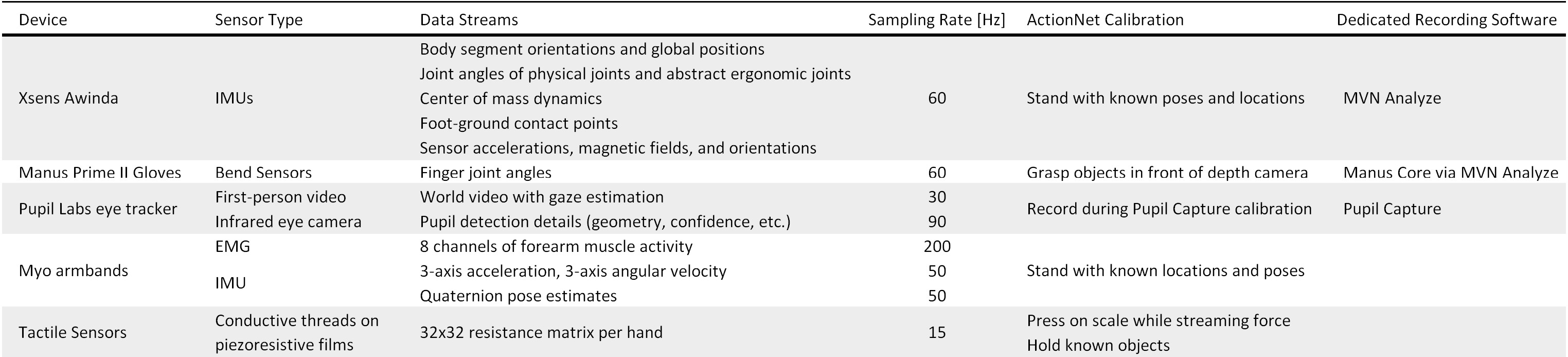
Body and Finger Tracking
The Xsens MTw Awinda system estimates body pose and position. It uses 17 wireless IMU modules worn on the body with elastic straps, a tight-fitting jacket, and a headband. Manus Prime II Xsens gloves augment the skeleton with hand poses by using embedded bend sensors.
The Xsens and Manus applications process sensor data in real time to estimate positions and orientations of each body and finger segment. The continuous ActionSense recordings include the third-party calibration periods comprising known poses and motions, as well as custom calibration periods featuring known global positions. These are performed at both the start and end of each experiment to help estimate drift.
During experiments, ActionSense records data that is streamed from the Xsens software via a network socket. In addition, the Xsens software can record all data in a proprietary format and then reprocess it after the experiment; ActionSense includes scripts to import these improved estimates and synchronize them with the rest of the sensor suite. The original data is also provided separately.
Limitations: These sensors provide wearable body and finger tracking, facilitating freedom of motion and larger workspaces. However, accuracy may be reduced when compared to external motion-tracking infrastructure. For example, the global positions inferred from the IMUs are observed to drift over time. Finally, the Manus gloves include IMUs that can be fused with the bend sensors, but current experiments disable them due to observed accuracy issues; this reduces the measured degrees of freedom to only capturing finger curling and not lateral finger spreading.
Eye Tracking
The Pupil Core headset by Pupil Labs features a wide-angle RGB camera to view the world, and an infrared camera aimed at the pupil. The Pupil Capture software detects the pupil orientation in real time and maps the estimated gaze into world-view image coordinates to estimate where the person is looking. The system is calibrated by requesting the user to gaze at a displayed target while moving their head to vary their eye orientation. ActionSense records data from all sensors during this process, to enable re-calibration or accuracy evaluation in post-processing.
The Pupil Capture software streams data to the ActionSense framework via network sockets during experiments, and can also save all data to dedicated files. ActionSense includes scripts to merge its recorded data into the main dataset after an experiment, to provide the most consistent sampling rates possible. The original streamed data and the raw recorded data are also available.
Limitations: The small wearable sensor provides valuable attention estimates, but it requires a USB cable; ActionSense uses a stretchable coiled overhead cable to reduce motion hindrance, and a wearable computer could eliminate the tether. In addition, current experiments use a single eye camera; leveraging binocular information may improve gaze accuracy. Finally, the wide-angle camera is adjusted to view as much of the task as possible, but does not fully span the subject's field of view.
Muscle Activity
A Myo Gesture Control Armband from Thalmic Labs is worn on each forearm. It contains 8 differential pairs of dry EMG electrodes to detect muscle activity, an accelerometer, a gyroscope, and a magnetometer. It also fuses the IMU data to estimate forearm orientation, and classifies a set of five built-in gestures. ActionSense wirelessly streams all data by leveraging a Python API. The device normalizes and detrends muscle activity without dedicated calibration, but forearm orientation estimates are relative to an arbitrary starting pose. To facilitate transforming these into global or task reference frames, the calibration poses include known arm orientations.
Limitations: The current sensor suite only includes muscle activity from the forearms, which are highly useful for the chosen manipulation tasks but which may not capture all relevant forces and stiffnesses. In addition, the estimated orientations may drift over time.
Tactile Sensors
Custom sensors on each glove provide tactile information. Conductive threads are taped to a pressure-sensitive material that decreases its electrical resistance when force is applied. Threads are oriented perpendicularly to each other on opposite sides of the material, such that each intersection point acts as a pressure sensor. Measuring resistance between each pair of threads yields a matrix of tactile readings. This technique has been explored previously for applications such as smart carpets.
The current implementation features 32 threads in each direction that are routed to form a 23x19 grid on the palm, a 5x9 grid on the thumb, an 11x4 grid on the little finger, and a 13x4 grid on each other finger. The readings are performed by a microcontroller and a custom PCB for processing and multiplexing. These are worn on the hand or arm, and data is streamed either via USB or wirelessly.
ActionSense provides two types of calibration to facilitate force or pose estimation pipelines. First, the subject presses on a Dymo M25 Postal Scale using a flat hand or individual fingers while weight readings are recorded from the scale via USB. The person then holds 5 unique objects. All sensors are recorded during these activities, including the depth camera and finger joint data.
Limitations:These flexible sensors provide high-resolution tactile information, but their sampling rate and material response time may preclude highly dynamic tasks. Calibration periods are designed to help interpret the readings, but accuracy when converting to physical units may vary over time. Finally, the tactile sensors do not reach the fingertips since the underlying gloves feature open fingers.
Ground Truth and Environment-Mounted Sensors

Interactive Activity Labeling
The ActionSense software includes a GUI that enables real-time labeling while accommodating unexpected issues or events. It allows researchers to indicate when calibrations or activities start and stop, and to mark each one as good or bad with explanatory notes. Entries are timestamped and saved using the common data format, so pipelines can extract labeled segments from any subset of sensors.
Cameras
RGB Cameras: Five FLIR GS2-GE-20S4C-C cameras provide ground-truth vision data of human activities. Four cameras surround the kitchen perimeter, while one camera is mounted above the main table. Images are captured at 22 Hz with 1600x1200 resolution. A custom ROS framework communicates with all cameras. Each camera is
calibrated using a checkerboard. The calibration result, raw-format frame images with timestamps, and generated videos are all included in the dataset.
Depth Camera: Since most of the chosen activities interact with objects on the table, detailed 3D information of this area can be helpful. We mount an Intel RealSense D415 Depth Camera in front of the kitchen island. We stream this depth camera at 15 Hz with 640x480 resolution. An Intel RealSense driver is used to communicate with the camera. Raw images and the depth pointcloud are recorded, and the extrinsic calibration information is also provided.
Limitations:
These cameras provide useful ground truth data about the activities in the kitchen environment, but there may be some areas that cannot be viewed while a subject is doing certain tasks (for example, inside the dishwasher). In such cases, the first-person camera may still provide vision data. In the future,
we plan to do multi-camera calibration for 3D reconstruction of the
environment.
Microphones
Two microphones provide audio information that can be used by learning, segmentation, or auto-labeling pipelines. One has an omnidirectional pickup pattern and is secured above the main table, while the other has a cardioid pickup pattern and is placed on the counter behind the sink. Since the environment is within a common lab space, background noise and speech may be included in the data; this could be a limitation or a benefit depending on the goals of future analysis pipelines.